Hierachical token bucket theory
Martin Devera aka devik (devik@cdi.cz)
Last change: 5.5.2002
Definitions
Let's define HTB's goal formaly. Some definitions first:
- Class has associated assured rate AR, ceil rate CR,
priority P, level and quantum Q. It can has parent.
We also know value of actual rate or R. It is rate of packet
flow leaving the class and is measured over small period. For inner classes
it is R sum of all descendant leaves.
- Leaf is class which has no children. Only leaf can hold packet queue.
- Level of class determines its position in hierarchy. Leaves
has level 0, root classes LEVEL_COUNT-1 and each inner class has level
one less than its parent. See pictures below (LEVEL_COUNT=3 there).
- Mode of class is artifical value which can be computed from
R,AR,CR. Possible modes are
- Red: R > CR
- Yellow: R <= CR and R > AR
- Green otherwise
- D(c) is list of all backlogged leaves which are descentants of c and where
all classes between such leaf (and including it) and c are yellow. In
other words D(c) is list of all leaves which would want to borrow from c.
Link sharing goal
Now we can define link sharing goal as definition for R.
For each class c it should hold
Rc = min(CRc, ARc + Bc) [eq1]
where Bc is rate borrowed from ancestors and is defined as
Qc Rp
Bc = ----------------------------- iff min[Pi over D(p)]>=Pc [eq2]
sum[Qi over D(p) where Pi=Pc]
Bc = 0 otherwise [eq3]
where p is c's parent class. If there is no p then Bc = 0. Two definitions
for Bc above reflects priority queuing - when there are backlogged descendants
with numericaly lower prio in D(p) then these should be served, not us.
Fraction above shows us that excess rate (Rp) is divided between all leaves
on the same priority according to Q values. Because Rp in [2] is defined again
by [1] the formulas are recursive.
In more human way we can say that AR's of all classes are maintained if there is
demand and no CR's are exceeded. Excess bw is subdivided between backlogged descendant
leaves with highest priority according to Q ratios.
Auxiliary delay goal
We also want to ensure class isolation. So that changes in rate of one class
should not affect delay in other class unless both are actualy borrowing from
the same ancestor. Also hi-prio class should has lower delays than lo-prio assuming
they are both borrowing from the same level.
CBQ note
If you look at [1] you will see that our goals are more restricted
subset of CBQ goals. So that if we can satisfy HTB goals than we also
satisfy CBQ's one. Thus HTB is kind of CBQ.
HTB scheduler
Here I will often put Linux implementation specific function or variable
names into parens. It will help you to read source code.
There is tree of classes (struct htb_class) in HTB scheduler
(struct htb_sched). There is also
global so called self feed list (htb_sched::row).
It is the rightmost column on
pictures. The self feed is comprised of self slots. There is
one slot per priority per level.
So that there are six self slots on the example (ignore while slot now).
Each self slot holds list of classes - the list is depicted by colored
line going from the slot to class(es). All classes in slot has the same
level and priority as slot has.
The self slot contains list of all green classes whose have
demand (are in D(c) set).
Each inner (non-leaf) class has inner feed slots (htb_class::inner.feed).
Again there is
one inner feed slot per priority (red-high, blue-low) and per inner class.
As with self slots there is list of classes with the same priority as
slot has and the classes must be slot owner's children.
Again the \ninner slot holds list of yellow children which are
in D(c).
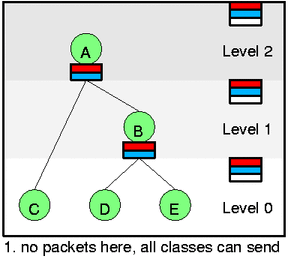
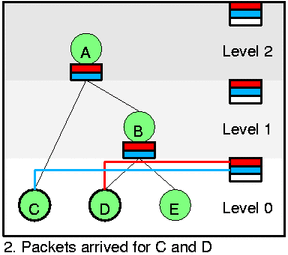
The white slot on self feed doesn't really belong there but it
was more convenient to draw it as such. It is wait queue per
level (htb_sched::wait_pq, htb_class::pq_node). It hold list of all classes on
that level which are either
red or yellow. Classes ar sorted by wall time (htb_class::pq_key) at
which they will change color (htb_class::mode). It is because the color change is asynchronous.
Probably you already see that if we are able to keep all cleasses on
correct lists then selecting of next packet do dequeue is very simple.
Just look at the self feed list and select the nonempty slot
(one with a line) with lowest level and highest prio. There is no
such one at pict 1. so that no packet can be send. On 2. it is red
slot at level 0 thus class D can send now.
Let's look closely at the first two pictures. At 1. there is no backlogged
leaf (all such leaves are drawn by thin circle) so that there is nothing
to do. At 2. packets arrived for both C and D. Thus we need to activate
these classes (htb_activate) and because they are both green we add them directly
to their appropriate self slots. Dequeue would select D now and continue
to C if it can't drain packet from C (unlikely).
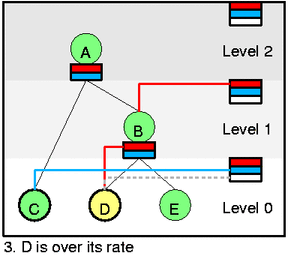
Let's assume that packet was dequeued (htb_dequeue) from D (htb_dequeue_tree)
and we charged the packet size to leaky bucket (htb_charge_class). It forced
D to go over its rate and changes color to yellow. As part of this change
(htb_change_class_mode) we need to remove it from self feed (htb_deactivate_prios
and htb_remove_class_from_row) and add to B's inner feed (htb_activate_prios).
It also recursively adds B to self feed (htb_add_class_to_row). Because D
will return to green state after some time we add it to priority event queue
(htb_add_to_wait_tree) at its level (0).
Dequeue would now select class C even if it is lower prio than D. It is
because C is at lower level and to compute [eq2] correctly we have to serve
lower levels first. It is also intuitively ok - why to borrow if someone
can send without it.
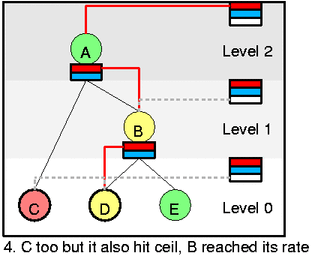
Let's assume that we dequeued C now and it changed state to red (ceil was
reached). In this state C can't even borrow. Also assume that some packets
was then drained from D and thus B changed to yellow. Now you should be
able to explain all steps: remove B from self list, add it to wait and
add A to self. Add B to A's inner feed. Add C to wait.
Now you can clearly see how self and inner feed list creates path for borrowing.
It is the line at pict 4. going from the top self slot down to D. And yes,
D is now the only one who can send.
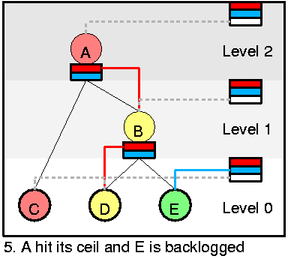
Let's complicate it more. A hits its ceil and E starts to be backlogged.
C returned to green.
Changes are trivial only you can see that inner feeds are maintained even
if the are not used. Look at the red feed which ends at A ... This picture
also shows that more than one class can be on the same feed.
E and C can be dequeued at the same time. To ensure correct distribution
by Q as requested in [eq2] then as long as this state persist we have to
apply DRR and cycle over both classes. It is simpler to say but harder to
do. Let's look closer at it.
The class lists attached to inner or self feeds are rb-trees in reality.
Hence each such list is sorted by its classid. Classid is constant for
hiven hierarchy. We remember for each self slot active class from the list
(htb_sched::ptr). Then it is fast to find leaf to dequeue - just follow
(htb_lookup_leaf)
ptrs from self feed thru inner feeds (htb_class::inner.ptr) to a leaf.
When DRR decides that its quantum was exhausted (htb_dequeue_tree) we
increment ptr (htb_next_rb_node) which led us to the leaf. The next
tree traversal (htb_lookup_leaf) will propagate the change to the upper
levels.
You can ask why the list should be sorted by classid. It is simple - DRR
theory assumes that backlogged class remain on the same position. Only
then DRR properties hold. In HTB the class migrates between lists too
often and this would adversely affect precision of ratios.
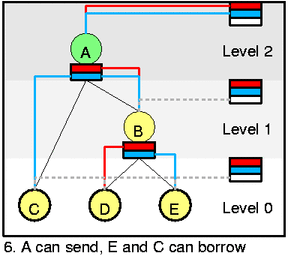
The last and very interesting picture. Three classes changed, A can send
E and C are yellow now. The important thing here is to understand that
inner class can be active for more priorities (htb_class::prio_activity)
while leaf only for one (htb_class::aprio). So that you can see red/blue
pair going from self feed to A and B and forking to D and E. Also you
can see the same as at 5. but with inner feed now. A serves both C and
B (and thus E) at blue/low prio. If there were not D active we would
have to dequeue C and E using DRR.
Implementation details
Paragraph above should be enough to understand the code. Only a few notes.
There are htb_sched::row_mask[level] which tells us which prios are active
on single level. For picture 6 the row_mask = { 0,0,3 }, for pict 3 it
would be { 2,1,0 }. It allows for faster eligible level lookup.
The htb_dequeue code applies all pending changes in even queue for the
level which is going to dequeue. It is also reason why event queue is
split per level - we need not to apply changes to level 1 or 2 classes as in
picture 5 when it is enough to apply only those from level 0 and then
dequeue level 0. It is because of fact that on higher level prio queue
can be no event which would prevent lower level from having green classes.
There is short-circuit for event existence test. Because we often need
to test whether there is event for this time I added htb_sched::near_ev_cache
per level which holds time of nearest event in jiffies. Fast test is
then enough. Typicaly 10-30% speedup.
Color is called mode in the code. Corelation is 0=Red=HTB_CANT_SEND,
1=Yellow=HTB_MAY_BORROW, 2=Green=HTB_CAN_SEND. It is computed in
htb_class_mode as leaky bucket [2]. Note the there is globaly defined
HTB_HYSTERESIS which adds hysteresis of "burst" size to the mode computation.
It means that there is less mode changes and I measured 15% speedup.
Waitlist presence rule. The class is on its waitlist everytime
when class mode is not HTB_CAN_SEND (Green).
Linux qdisc should support explicit drop request. It is very hard to do
it here so that I have to add special htb_class::leaf.drop_list along with
htb_sched::drops list per priority. These holds all active classes for
given level. During drop I select the first one from lowest prio active
list.
HTB uses "real" DRR as defined in [4]. CBQ in Linux uses one where the
quantum can be lower than MTU - it is more generic but it is also no longer
O(1) complexity. It also means that you have to use right scale for
rate->quantum conversion so that all quantums are larger than MTU.
Acknowledments
I'd like to say thanks to numerous people from Linux world who helped
and motivated me a lot.
[1] Link-sharing and Resource Management models for Packet Networks,
Sally Floyd and Van Jacobson, 1995
[2] Leaky Bucket, J. Turner, IEEE vol 24 1986
[3] HTB for Linux, http://luxik.cdi.cz/~devik/qos/htb
[4] Efficient Fair Queuing using Deficit Round Robin, M. Shreedhar and G. Varghese
[5] WF2Q: Worst-case Fair Weighted Fair Queuing, J.C.R. Bennet and Hui Zhang