I got the idea while reading Floyd's paper about CBQ. I suddenly realized
that I can create algorithm which solves goals of link sharing given in
Floyd'd paper (called formal guidelines) and the algorithm is simpler
more robust and more precise that top-level algorithm.
It was 1.9.2001.
3.9. I implemented basic idea
4.9. first results are here about 10 oops repaired.
5.9. (today) tested real link sharing which surprisingly behaves better
than I ever expected
Some important observations here. When class A has higher priority than B and both are borrowing from C then A gets as much as it can and remainder is served to B (but B still gets its own rate). If B has the same priority as A then borrowed bandwidth from C would be divided between A and B in the same proportion as their own base rates are.
The CBQ solves the goal by maintaining top-level variable and cycles only
over leaves. At each leaf try to borrow from ancestors up to level
top-level. When you update top-level to be upper level below which
there are no leaves which could send without borrowing (unsatisfied
in Floyd's terms) then result is essentialy the same. Top-level is
faster but less precise way.
The "rate conformness" is measured by measuring time between packet
edges. Note that it is very hard to implement precisely.
In HTB I use the "abstraction" above directly. I really cycle over
leaves more times. It is slower but is allows me to do thinks more
precisely (I implement private DRR values for each level).
It uses TBF estimators which are easy to implement even on hardware
without tsc (still with reasonable precision).
I added notion of ceil rate (ceil of rate the class can ever get).
So that the class can always use bandwidth between its base and
ceil rate values.
It is simply implemeted by disallowing borrowing when class is over
this rate (both leaves and interiors can have ceil). Note that when
ceil is tha same as base rate it is the same as bounded keyword
in CBQ.
0 P 0 0x10002 # set flow's 0 and 1 SO_PRIORITY which qdisc 0 P 1 0x10003 # can use to switch between classes 1:2 and 1:3 0 S 0 1000 # both flows has pasket size 1kB 0 S 1 1000 0 R 0 90000 # start flow 0 generating 90 kBps 4000 R 1 50000 # at time 4s start flow 1 at 50 kBps #7000 R 1 70000 9000 R 0 0 # at 9s stop flow 0 14000 X 0 0 # at 14s terminate measuringIMO it is intuitive.
tc qdisc add dev eth0 root handle 1: cbq bandwidth 10Mbit avpkt 1000 tc class add dev eth0 parent 1: classid 1:1 cbq bandwidth 10Mbit rate 100kbps maxburst 10 bounded avpkt 1000 tc class add dev eth0 parent 1:1 classid 1:2 cbq bandwidth 10Mbit rate 40kbps maxburst 10 avpkt 1000 weight 4 prio 1 tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 10Mbit rate 20kbps maxburst 10 avpkt 1000 weight 2 prio 1 tc qdisc add dev eth0 parent 1:2 handle 20: pfifo limit 5 tc qdisc add dev eth0 parent 1:3 handle 30: pfifo limit 5Note the pfifos. These MUST be used because we send skbs from raw socket so that all packets sitting in queues are accounted against the socket. When you leave default 100 packet queues then send() syscall starts to block and measuring is imprecise (my simulator notices it and warns).
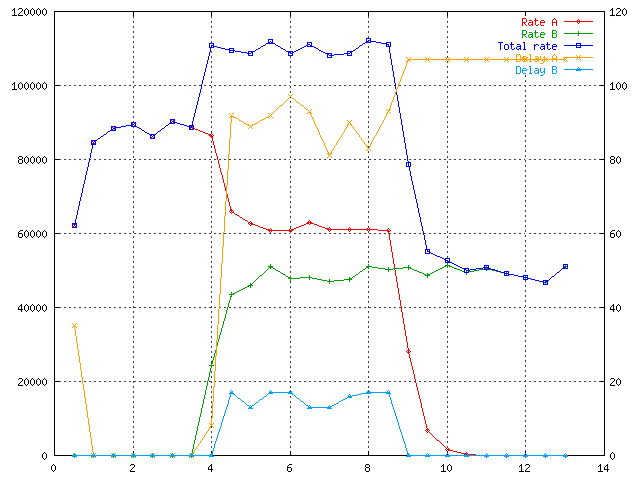
Above you see result. First notice that total rate is higher than 100 kBps. It is ewma-idle error. The shared rate is ok. According to weights the class A should get two times more than B:
rA = 40 + 40*2/3 ~= 67 kBps rB = 20 + 40*1/3 ~= 33 kBps
Well let's look how to use priority value. I changed "prio 1" for 1:3 to
"prio 0" to boost the class. Because generator generates 50 kBps for 1:3
and class A (1:2) has quaranted 40 kBps there is room bellow 100 kBps and
class A should experience NO delay.
As you see it is almost right. Delay is not zero but is reasonably small.
tc qdisc add dev eth0 root handle 1: htb depth 2 AC="tc class add dev eth0 parent" $AC 1: classid 1:1 htb rate 100kbps burst 2k $AC 1:1 classid 1:2 htb rate 40kbps ceil 80kbps burst 2k prio 1 $AC 1:1 classid 1:3 htb rate 20kbps ceil 80kbps burst 2k prio 1 tc qdisc add dev eth0 parent 1:2 handle 20: pfifo limit 5 tc qdisc add dev eth0 parent 1:3 handle 30: pfifo limit 5This is the same setup. I will debate the ceil parameter bellow.
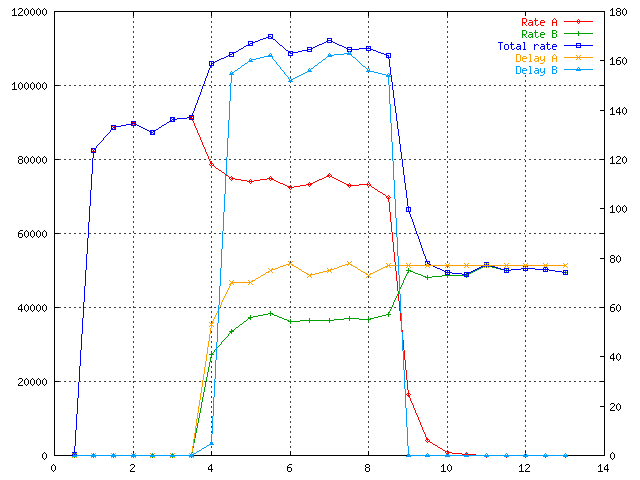
You can see that traffic looks very similar. Let's discuss ceil setting.
At time 1 to 3 only class A sends 90 kBps. The spike at 2 is due to
"burst 2k" parameter. Then the flow is limited to 80 kBps mandated by
ceil. So that class has its 40 kBps always and can borrow from parent
up to 80 kBps. So that neither A nor B can saturate whole link.
At 4 B starts transmit and again as with CBQ the bandwidth is divided
correctly but the 100 kBps limit is more precise.
The delay of B at 5 is a bit worse than with CBQ but it is about 15%.
I'm not sure about reason.
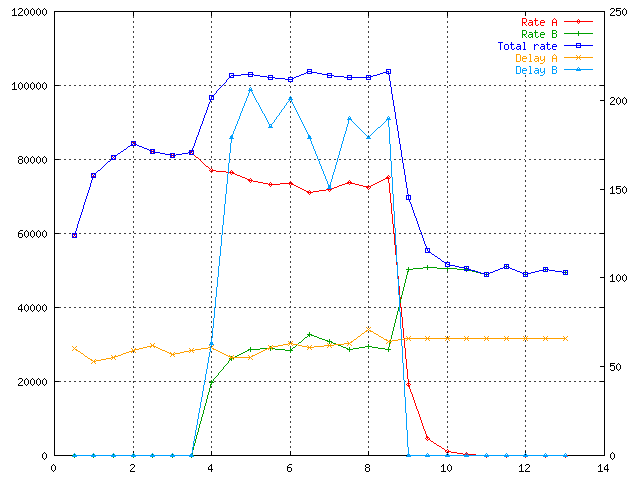
What about priority:
Nothing interesting only as you can see the B's delay is impressive :-)
I tested cross device sharing. There are problems with sharing bw
borrowed from another device because we can't tell foreign device when it
should dequeue.
So that I added rate meter (which you can see in tc show) and implemented
heuristic weak sharing control. It simply calculates "ideal" rate which
class should get (computed from rates of active classes) and deny borrowing
from "slot" (see description of cross sharing) if actual rate is higher.
Let's see how it works in real. I have the same testing bed as described
above. There is new generator setup:
0 i 0 eth0 0 i 1 eth0 0 i 2 eth1 0 P 0 0x10002 0 P 1 0x10003 0 P 2 0x10002 0 S 0 500 0 S 1 500 0 S 2 500 0 R 0 90000 2000 R 2 70000 4000 R 1 50000 9000 R 0 0 14000 X 0 0The new "i" command binds output interface to flow. And qdisc setup:
tc qdisc add dev eth0 root handle 1: htb depth 2 tc qdisc add dev eth1 root handle 1: htb depth 2 AC="tc class add dev eth0 parent" $AC 1: classid 1:1 htb rate 50kbps ceil 100kbps burst 2k pslot 1 $AC 1:1 classid 1:2 htb rate 30kbps ceil 100kbps burst 2k $AC 1:1 classid 1:3 htb rate 10kbps ceil 100kbps burst 2k AC="tc class add dev eth1 parent" $AC 1: classid 1:1 htb rate 800000 burst 2k slot 1 $AC 1:1 classid 1:2 htb rate 30kbps ceil 100kbps burst 2k tc qdisc add dev eth0 parent 1:2 handle 20: pfifo limit 2 tc qdisc add dev eth0 parent 1:3 handle 30: pfifo limit 2 tc qdisc add dev eth1 parent 1:2 handle 20: pfifo limit 2You can see we have one "general" super-parent 1:1 on eth1 which offers it's bandwidth to cross device sharing (by "slot 1" parameter). It has 100kBps. It has direct child 1:2.
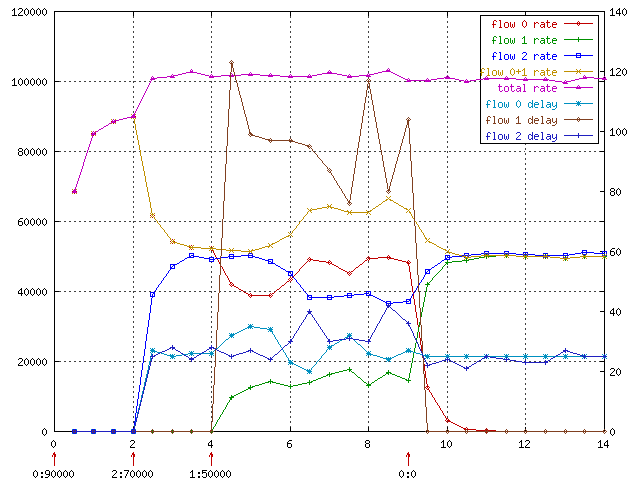
As you can see I've invented new gnuplot script which renders R events
bellow x axis as band:new_rate. The generator's off by 0.5 problem is
solved too.
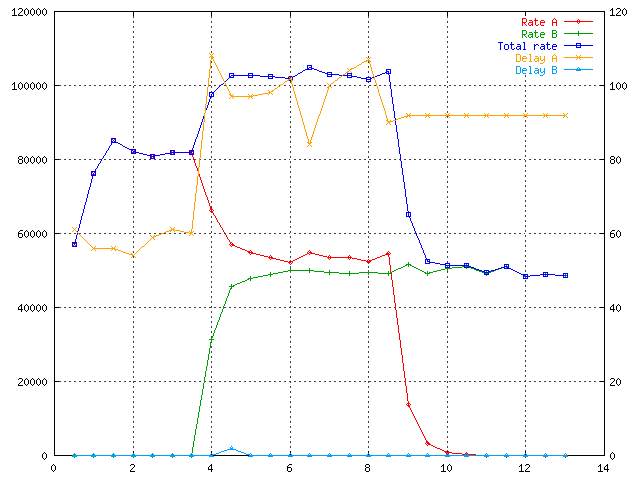
At time 3.5 you can see flow 0 (eth0) and 2 (eth1) getting almost the same
share but the should get 50:30 ratio. Why ? The cross device sharing
is based on rate estimator with 6 sec averaging interval. It simply
did not catch up yet.
At time 6 is starts to estimate well and ratio is correct (yellow vs.
blue line).
As you see the ratios and total bandwidth is maintained very well now.
I hope that how we need only to catch bugs :).
I need someone to consult inter-qdisc locking issues.
I need testers.